원래 2편 정도로 끝내려 했는데 3편까지 오게 되었다.
3편에서는 본격적으로 코드를 살펴보며 크롤링을 진행하고자 한다.
먼저 2편에서 chrome driver와 selenium, bs4 패키지 설치가 되었다면
다음과 같은 모듈들을 import 해 잘 설치가 되었는지 확인한다.
import os
from bs4 import BeautifulSoup
from selenium import webdriver
#import requests #request+bs4 조합만으로도 crawling가능
import time여기까지 별 이상이 없다면 이제 크롤링을 위한 준비물은 다 챙긴 것이다.
base_url = 'https://comic.naver.com/webtoon/weekday.nhn'
#chrome_dirver가 있는 위치
os.chdir('C:/Users/ursename/chromedriver_win32') #크롬드라이버.exe가 있는 폴더웹툰 크롤링을 위해 기본으로 사용할 url을 지정해 주었고, os 모듈을 이용해 크롬 드라이버를 불러오기 위한 기본 세팅을 해 주었다. 현재 working directory를 변경해 준 것이다.
#driver 실행
def drive(url):
driver = webdriver.Chrome('./chromedriver') #driver 객체 불러옴
driver.implicitly_wait(3) # 3초 후에 작동하도록
driver.get(url) #url에 접속
html = driver.page_source #현재 driver에 나타난 창의 page_source(html) 가져오기
soup = BeautifulSoup(html, 'html.parser') #html 파싱(parsing)을 위해 BeautifulSoup에 넘겨주기
return driver, soupdriver를 실행하기 위한 함수를 만들었다. 이 함수를 통해 크롬 웹드라이버를 실행시키고 함수 인자로 url을 넣어주어 해당 url에 접속하여 서버로 붙어 받아온 페이지 소스를 BeautifulSoup에게 넘겨 처리하기 쉽도록 변형한 후 driver와 soup를 반환한다.
#웹툰 기본 페이지에서 데이터 가져오기
driver, soup = drive(base_url)
driver.close()
#가져온 데이터 파싱, id, 요일, 이름
title = soup.select('.title')
t_IDs=list(map(lambda x: x.get('href').split('titleId=')[1].split('&')[0], title))
t_weekdays = list(map(lambda x: x.get('href').split('weekday=')[1], title))
t_names = list(map(lambda x: x.text ,title))
#크롤링이 잘 되었나 확인하기 위함, 총 웹툰 수
print('t_IDs: ',len(t_IDs))
print('t_weekdays: ',len(t_weekdays))
print('t_names: ',len(t_names))
print(t_IDs[0],t_weekdays[0], t_names[0])
웹툰 페이지(모든 웹툰들이 나열된)에서 html을 받아온다.(soup에 그 html데이터가 담겨있다.)
가져온 페이지 데이터에서 titleId, 와 weekday(요일)을 추출하는 코드이다.
우선 soup.select(패턴)을 통해 class='title'인 태그들을 가져올 수 있다.
그리고 가져온 태그는 리스트 형식으로 저장된다. 이 리스트에 대해 lambda함수와 slicing 기법을 적용해 적절히 분리 후 map(), list()함수를 사용해 다시 리스트로 만드는 작업이다.
이 작업을 통해 생성된, t_ID, t_weekdays, t_names 리스트들은 같은 index를 공유한다. 즉 t_names의 0번 인덱스 값이 '신의 탑'이면 t_ID[0]은 신의 탑의 ID이고, t_weekdays[0]은 신의 탑 요일값을 갖는다.
list(map(lambda ~)))는 자주 사용되는 패턴의 코드이다. 알아두면 좋다.
잘 모르겠다면, 다음 코드를 한 번 살펴보자.
list(map(lambda x: x*x, [1,2,3,4]))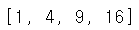
위의 코드는 리스트 [1,2,3,4]에 대해서 각 원소를 꺼내어 제곱한 후에 map(), list()를 거쳐 제곱된 결과들을 묶어 다시 리스트로 반환하는 코드이다.
lambda의 경우, 함수를 단순화 할 수 있으며, 순환 가능한 객체에 대해 각 원소들에 대해 연산을 적용하고자 할 때 편리하다. 다음가 같은 형식을 갖는다.
lambda y: y에 대한 함수, 순환 가능한 객체(리스트, 튜플 등)
추가로, split() 함수에 대한 설명은 다음 링크에서 확인할 수 있다.
#웹툰 이름으로 id와 weekday 반환
def find_id_weekday(name,t_names,t_IDs,t_weekdays,start_idx = 0):
try:
idx = t_names.index(name)
except:
print('찾는 웹툰이 없습니다.')
return
return t_IDs[idx], t_weekdays[idx]
이제 얻어낸 t_names, t_ID, t_weekdays가 같은 인덱스를 공유한다는 특징을 이용해 웹툰 이름을 입력해 해당 웹툰의 id와 weekday값을 알아내는 함수를 만들었다.
#episode 개수 세기
def episode_count(ID, weekday):
url = base_url.split('weekday')[0]+'list.nhn?titleId={0}&weekday={1}'.format(ID, weekday)
#print(url)
driver, soup = drive(url)
driver.close()
res = soup.select('.title')[0].select('a')[0].get('href').split('no=')[1].split('&')[0]
return res
res = episode_count(183559, 'mon') #신의 탑
print(res)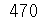
총 에피소드의 수를 세는 함수이다. 알아낸 id와 weekday 정보를 활용해 해당 웹툰의 목록 페이지에서 가장 최근에 나온 회차의 링크에서 몇회차 인지 추출해 낸다.
웹툰 '신의 탑'으로 테스트 해보았다.
def comment_crawler(name, start_idx=0):
id_num, weekday = find_id_weekday(name,t_names,t_IDs,t_weekdays, start_idx=start_idx)
cnt = int(episode_count(id_num, weekday))
comments = []
proceed = -1 #진행 상태 표시 위함, 처음에 0보다 작아야 0%가 표시 됨
driver, _ = drive(base_url) #driver만 먼저 열어 놓음. for문 돌면서 url만 바꿔줄 것임
print('진행중...')
for i in range(1,cnt+1):
percentage = int((i/cnt)*100)
if percentage%10==0 and percentage>proceed: # 진행상황 표시
proceed = percentage
print(proceed, '% 완료')
url = 'https://comic.naver.com/comment/comment.nhn?titleId={0}&no={1}#'.format(id_num, str(i))
#driver.implicitly_wait(3)
time.sleep(1.5)
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
comments += list(map(lambda x: x.text, soup.select('.u_cbox_contents')))
driver.close()
print('crawling finished')
return commentscomments = comment_crawler('외모지상주의')
가장 중요한 함수이다. 지금까지 알아낸 웹툰 id, 총 회차 수를 바탕으로 댓글 크롤링을 진행한다. for loop를 돌면서 각 회차 당 html source를 받아오고 이를 분석하여 (2편에서 알아낸 태그와 lambda,map, list이용) comments 리스트에 계속 추가해 나간다.
for loop 도중에 진행상황을 확인할 수 있도록 코드를 추가하였다.
html 태그 분석에 있어서 사족을 붙이자면, 태그에서 데이터를 추출하는 데 중요한 역할을 하는 것은 css 태그이다. class와 id 등 여러 종류가 있는데 이들을 css selector라고 부른다. 우리가 특정 태그를 선택하기 용이하게 해주는 표식들이다. 이 태그들을 잡아내는 패턴들은 다음 링크에서 찾아볼 수 있다.
https://www.w3schools.com/cssref/css_selectors.asp
www.w3schools.com
#수집된 댓글 수
print(len(comments))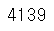
#추출한 댓글 저장 위해 현재 working directory 변경, 저장할 폴더 위치로 지정하면 된다.
os.chdir('C:/Users/Username/webtoon_comments')file = open('외모지상주의_comments.txt', 'w', encoding='utf-8')
for cmt in comments:
file.write(cmt+'\n\n')
file.close()크롤링한 댓글들을 댓글마다 '\n\n'으로 구분하여 txt파일로 저장하는 코드이다.
'컴퓨터' 카테고리의 다른 글
| [컴퓨터 구조] Assembly language for MIPS instructions (0) | 2020.04.05 |
|---|---|
| 컴퓨터 용량 단위(SI prefix, Metric prefix) (0) | 2020.03.22 |
| 네이버 웹툰 베스트 댓글 크롤링-2 (0) | 2020.03.01 |
| 네이버 웹툰 베스트 댓글 크롤링-1 (0) | 2020.03.01 |
| positional encoding이란 무엇인가 (5) | 2020.02.20 |


댓글